На цей час не знаю як перманентно полагодити цю проблему, але позиційне рішення просте
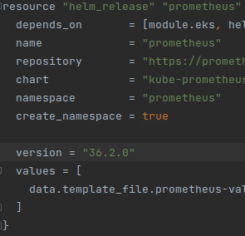
В моєму випадку керування інфраструктурою іде через terraform, проблема стосується ситуації (Multi-Attach error for volume), коли у тебе є зовнішній том (розділ) – який ти прикручюєш до поди, наприклад Prometheus або Jenkins, коли іде з якоїсь причини перестворення серверу (node) – том має бути примонтовано, але якщо том створено в одній AZ а сервер в інщій – виникає ця проблема. Для її вирішення можна зробити відмітку для ресурса що він “поганий”, або перестворити його.
Перший варіант рішення проблеми виставити ресурс як працюючий не належним чином:
|
1 2 |
terraform taint module.eks-cluster.helm_release.prometheus terraform plan && terraform apply |
Другий варіант рішення проблеми, перестворення ресурсу, який з проблемами:
|
1 2 |
terraform destroy -target module.eks-cluster.helm_release.prometheus terraform apply |
Після відпрацювання зазвичай проблема вирішується.

![Cluster health status changed from [RED] to [YELLOW]](https://demi4.com/wp-content/uploads/2019/03/Screenshot_2019-03-14_14-01-26.png)
