Часто натыкаюсь в своей практике на аппаратные рейды HP и постоянно потом сижу и втыкаю в документацию какпроверить винты, как првоерить рейд…
Сначала качаем и устанавливаем hpacucli – утилиту для управления аппаратным рейдом на серверах HP:
Для Centos 64 bit выложил у себя что бы качать сразу со своего сервера, а то странная политика у HP не дают качать по прямым ссылкам со своих серверов, приходится извращаться.
Сквчать можно отсюда – hpacucli
или вот так:
|
1 |
wget http://demi4.com/wp-content/uploads/2014/09/hpacucli-9.10-22.0.x86_64.rpm |
Далее устранавливаем:
|
1 |
yum install hpacucli-9.10-22.0.x86_64.rpm |
После установки можно начинать проверять и химичить:
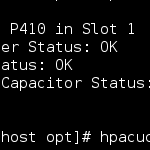
Проверить статус контроллера:
|
1 2 3 4 5 6 |
hpacucli controller all show status Smart Array P410 in Slot 1 Controller Status: OK Cache Status: OK Battery/Capacitor Status: OK |
Увидев что с контроллером все ОК и что он находится в Slot 1 можно проверить статус логических дисков:
|
1 2 3 4 5 6 7 8 9 10 |
hpacucli controller slot=1 logicaldrive all show status logicaldrive 1 (279.4 GB, RAID 0): OK logicaldrive 2 (279.4 GB, RAID 0): OK logicaldrive 3 (279.4 GB, RAID 0): OK logicaldrive 4 (279.4 GB, RAID 0): OK logicaldrive 5 (279.4 GB, RAID 0): OK logicaldrive 6 (279.4 GB, RAID 0): OK logicaldrive 7 (279.4 GB, RAID 0): OK logicaldrive 8 (279.4 GB, RAID 0): OK |
Видим что с логическими исками все в норем, можно проверить и статус физичемких дисков:
|
1 2 3 4 5 6 7 8 9 10 |
hpacucli controller slot=1 physicaldrive all show status physicaldrive 1I:1:1 (port 1I:box 1:bay 1, 300 GB): OK physicaldrive 1I:1:2 (port 1I:box 1:bay 2, 300 GB): OK physicaldrive 1I:1:3 (port 1I:box 1:bay 3, 300 GB): OK physicaldrive 1I:1:4 (port 1I:box 1:bay 4, 300 GB): OK physicaldrive 1I:1:5 (port 1I:box 1:bay 5, 300 GB): OK physicaldrive 1I:1:6 (port 1I:box 1:bay 6, 300 GB): OK physicaldrive 1I:1:7 (port 1I:box 1:bay 7, 300 GB): OK physicaldrive 1I:1:8 (port 1I:box 1:bay 8, 300 GB): OK |
С ними то же все в норме, по хорошему я сразу пускаю проверку дисков через Smart:
for i in $(seq 0 7); do smartctl -a /dev/sg0 -d cciss,$i -t long; done
и иду гулять на несколько часов пока идет проверка дисков, после проверки проверяю все ли в норме с исками, в зависимости от производителя дисков, версии smart проверяю или параметры 5 и 196 что бы были по нулям, или просто статус проверки, пример нормальной проверки на картинке ниже:

Если датацентр или хостеркак всегда накосячили с настройками рейда, создаю и запускаю в работу сам:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 |
# logical drive - one disk hpacucli> ctrl slot=1 create type=ld drives=1:12 raid=0 # logical drive - mirrored hpacucli> ctrl slot=1 create type=ld drives=1:13,1:14 size=300 raid=1 # logical drive - raid 5 hpacucli> ctrl slot=1 create type=ld drives=1:13,1:14,1:15,1:16,1:17 raid=5 Note: drives - specific drives, all drives or unassigned drives size - size of the logical drive in MB raid - type of raid 0, 1 , 1+0 and 5 |
Переподключеие диска который в статусе с ошибкой, иногда помогает если какие то глюки в системе:
|
1 |
hpacucli> ctrl slot=1 ld 4 modify reenable forced |
Ну и так по мелочи химичим:
|
1 2 3 4 5 6 7 8 9 10 11 |
Удалить логический диск: hpacucli> ctrl slot=0 ld 4 delete Расширить рейд (добавить дисков) hpacucli> ctrl slot=0 ld 4 add drives=2:3 Расирить размер рейда: hpacucli> ctrl slot=0 ld 4 modify size=500 forced Добавить запасной диск: hpacucli> ctrl slot=0 array all add spares=1:5,1:7 |
Мониторить статус рейда можно самым простым способом, пускать через cron простой скриптик проверки статуса контроллера, логических дисков и физических дисков через hpacucli и слать вывод себе на почту.

Во всех доступных доках по hpacucli говорится, что команда reenable деструктивна для данных и сама команда выдает предупреждение. Но если она действительно удаляет данные, зачем она тогда нужна? Если уж данные не важны, развалившийся (выпавший в FAILED) логический диск можно просто уничтожить и создать заново. Столкнулся со случаем падения RAID-5 из-за плохих контактов в разъемах дисков. Контакты почистили, диски надежно вставили, но контроллер упорно блокирует доступ — FAILED, а бекап староват.
У меня на практике reenable не уничтожала данные. Но практики с HW рейдами у меня не много, в тех нескольких разах что делал все было в норме.